.webp)
Hybrid Learning
.webp)






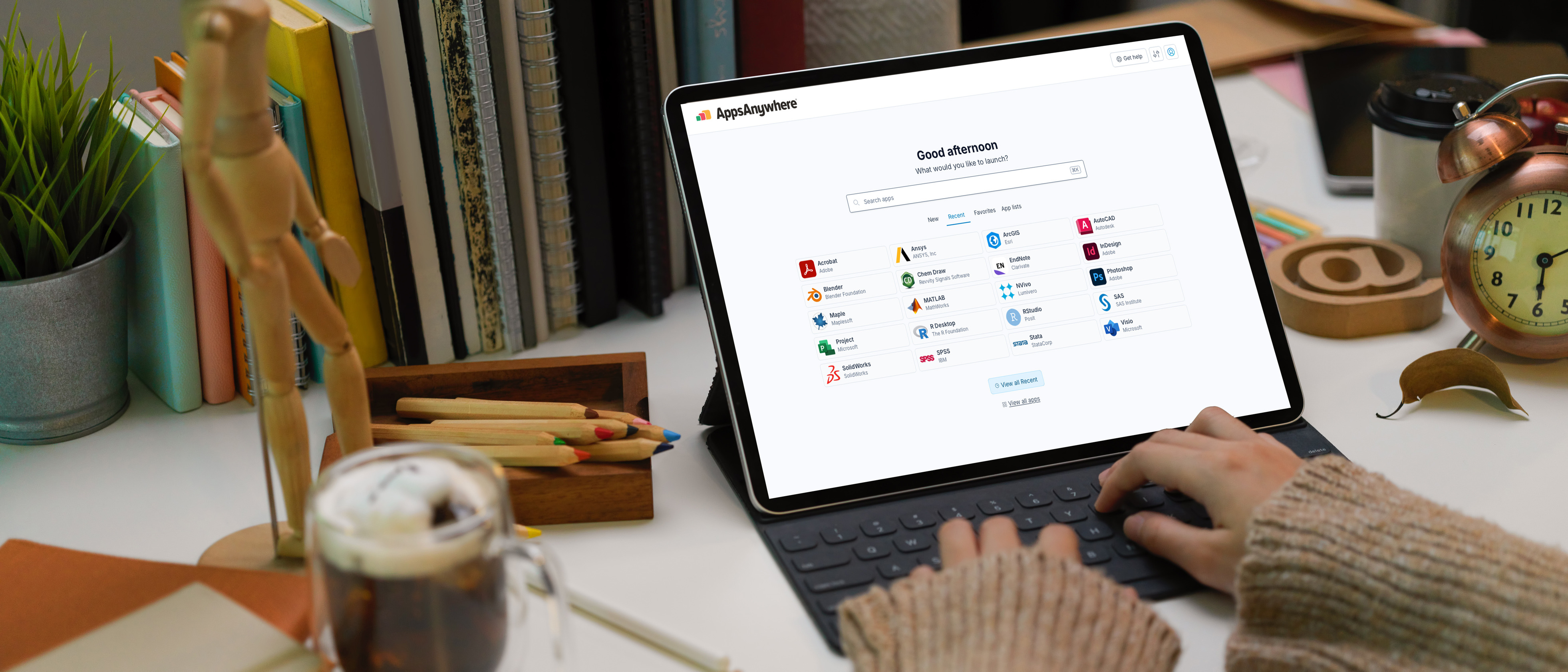
.jpg)





.webp)

.webp)

































.jpg)
































































.webp)




Resource Centre
Our Resource center has everything you need to know about application virtualization, software delivery, VDI and End-User Computing in Education IT.
Exploring the world of software delivery and deployment through thought-leadership insight, expert advice, and the latest software delivery news.

Register your interest for a demo and see how AppsAnywhere can help your institution. Receive a free consultation of your existing education software strategy and technologies, an overview of AppsAnywhere's main features and how they benefit students, faculty and IT, and get insight into the AppsAnywhere journey and post launch partnership support.